DataLend: Behind the Scenes

By Matt Ross, Product Specialist, DataLend
ON THE SURFACE, DataLend may seem like a fairly straightforward product: The system takes in some data from users and returns some data to users. However, when you look under the hood you quickly realize that processing and distributing this data is no easy task. DataLend has been built up over the last six years to include many complex processes, rules and algorithms to ensure the dataset is the cleanest, most accurate and most complete dataset in the securities finance industry.
How are “fat fingered” trades identified and segregated so they don’t impact overall loan balances or fees? How is each user firm reviewed to ensure they are sending in accurate and complete data? What data cleansing algorithms and other processes are in place to deliver information to our clients quickly and accurately? Read on to find out as we answer these questions and more (without giving away the full recipe to the secret sauce, of course)!
On average, DataLend processes over eight million records per day when looking across all outstanding loan and availability records submitted by our clients globally. Ensuring that all of that data is processed, cleansed, aggregated, anonymized and available in a meaningful and timely manner by the time users log in each morning and throughout the day requires the resources and coordination of multiple teams and individuals within the EquiLend organization. These include:
DataLend Product Specialists: The front line of DataLend, the product specialists work directly with clients to demonstrate the tools available within the suite of DataLend products and gather feedback to build requirements and develop a roadmap for future product enhancements. Product specialists have a hand in every facet of the product. They also help to design and test data processing and cleansing algorithms while keeping a keen eye on market events globally.
DataLend Engineers: The brains behind DataLend, the engineering team writes all of the code that builds the DataLend products, processes daily client files, manages the front-end Web design and handles all the steps in between. They work closely with the product specialist team to ensure that user requirements are fulfilled.
DataLend Database Administrators (DBAs): The logistical masterminds of DataLend, the DBAs determine how and where the data will be stored and the fastest and most reliable ways to access the data. They are also responsible for sourcing all of our third-party vendor data, such as security reference data, which is used to further enrich the DataLend data set.
DataLend Quality Assurance (QA): The “devil is in the details” team for DataLend, the QA team makes sure that for every change or enhancement made to the system, something else isn’t broken. They help ensure that users have a smooth and enjoyable experience while using DataLend by testing every nook and cranny in the system.
DataLend Client Services: The support center for DataLend, the client services team is here to help with everything from onboarding clients to answering client calls when they are having trouble accessing the system.
With each team’s roles and responsibilities defined, the fun can begin, and the focus can turn to the most important thing: our clients! In addition to ensuring DataLend meets and exceeds the needs of our clients, we also ensure that we are seeing a client’s entire book.
When onboarding new clients to DataLend, experts from both the Product Specialist and Client Services teams are assigned to not only assist the clients with the technical aspects of how and when to share their data, but also to ensure that the data is complete, accurate and contains all of the necessary fields used to generate the resulting data set. DataLend takes great pride in the quality of data delivered to our clients, and that’s why clients are required to include as part of their inbound contract file the counterparty with whom they are trading. This piece of information is not only crucial to DataLend’s deduplication logic, which ensures that only one side of every transaction is counted, but it also ensures that clients are submitting all of their trades by doing comparisons across each organization to determine if both sides of a given transaction are received. This information also helps us to display to end users when they have loans with specific counterparties may have rebate rates or fees away from current market conditions, enabling them to seek rate relief or rerate opportunities. Upon receiving data from a new client, the onboarding teams must then understand the logic needed to interpret the data as no two client files are the same. There can be differences in file structures, types, available data points in each file and other data challenges. Once that business logic is determined, it is handed over to the Engineering team, which writes custom code for every client’s file that is processed to ensure all aspects of each and every trade are accurately captured.
Once the onboarding process is complete and we are processing a daily open contracts file (and an availability file for agent lenders), multiple lines of defense are put in place to ensure that bad data is identified and removed from the system. Our Client Services team is the first into action if there are any missing files. They will receive an automated alert if a file from a client has not been received at the usual scheduled time. When this occurs, they will collaborate directly with the IT support team at the applicable firm to identify and rectify the issue.
After the client file is received, multiple checks are run on the file itself. Has the physical size of the file changed by a noticeable amount? Has there been a statistically significant change in the number of records or has the notional value of the file changed materially? If any of these scenarios are encountered, the Product Specialist team is notified and reaches out directly to the front office and IT teams of the submitting firm to determine if these changes are valid. If they are not, the team works with the submitting firm to resolve the issue immediately.
After a file makes it through the first line of defense in our system, it is then time to validate the content of the file row by row. Each transaction is scrutinized to ensure that there are no suspicious entries in the file. Many transaction-level checks occur, with each one designed to ensure our data set is accurate and represents the true nature of the securities lending market. There are the simple ones to ensure a transaction can be processed, such as determining if a mandatory field is missing or invalid. But the real fun begins when we try to identify those pesky fat-fingered trades or mispriced transactions.
Our custom algorithms will analyze recent trading patterns for a given security and determine what an acceptable range is for fees and rates for new transactions. If a fee or rate falls outside of that range, that trade is removed from our resulting volume-weighted average fee calculations. Third-party data is also employed to track recent and upcoming corporate events in order to properly detect and segregate trades that may be impacted due to these events.
Beyond those checks, DataLend employs a variety of other algorithms and business logic to ultimately produce the cleanest and most accurate set of transactions and availability records used in our final result set. Once all outlier checks and transaction validations are complete, DataLend begins the process of aggregating and anonymizing the data so it can be consumed by our clients to truly understand where a security is trading in the securities finance market, and perhaps equally as importantly, for a client to determine how their firm is positioned.
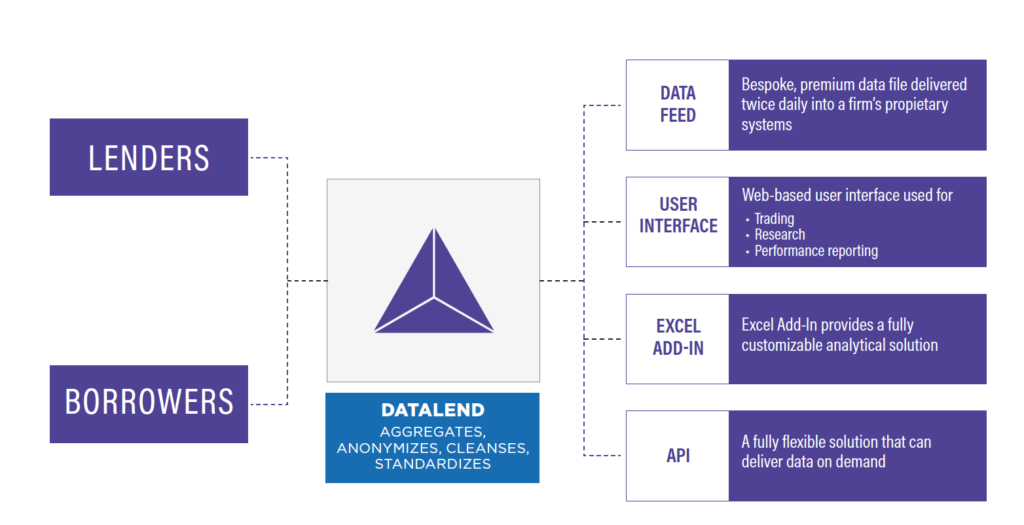
It is important that DataLend users have the flexibility to ingest the data in a way that is most beneficial to them. That is why there are myriad routes to market with DataLend data.
Users can access the Web-based user interface to do in-depth analysis on individual securities, or they can view macro-level trends across various asset classes, sectors, countries and regions to see how the industry is reacting to the latest news. Users can also create customized reports sent every morning in Excel files from the Research Reports screen.
Daily data feeds are retrieved, processed and stored by client proprietary systems at the individual security level or at the security, dividend rate and currency level. The new DataLend API allows users the most flexibility, enabling them to pull down the precise data points they require for any security across two years’ worth of history. Finally, the Excel Add-In tool allows users to import DataLend data alongside their own proprietary information.
DataLend wants our users to get the most value out of the data as possible, and the team is always thinking of new ways to deliver the data in a fast and efficient manner.
Based on the hard work of multiple teams throughout our organization, and especially due to constructive client feedback, DataLend has been able to deliver a valuable and award-winning service to securities finance market participants for the past six years. Let us know what you’d like to see developed next!